In the news
Read about Pathway’s latest media mentions, press releases and more!
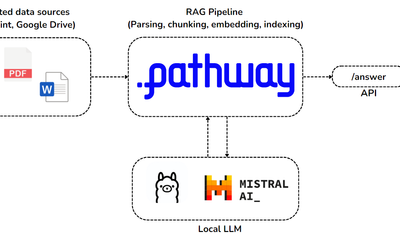

showcase · llmApr 23, 2024
Private RAG with Adaptive Retrieval using Mistral, Ollama and Pathway

blogApr 19, 2024
Machine Unlearning for LLMs: Build Apps that Self-Correct in Real-Time 
blogApr 18, 2024
Batch processing vs stream processing
case-studyApr 16, 2024
The Power of Real-Time Visualization for Logistics IoT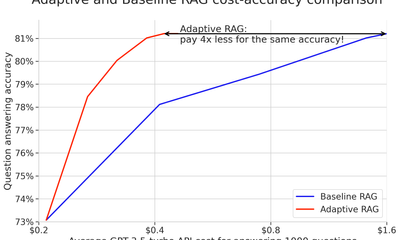

showcase · llmMar 28, 2024
Cheap RAGs up for grabs: How we cut LLM costs without sacrificing accuracy?
blogMar 21, 2024
Supply Chain Optimization with Integrated IoT Data
blogMar 7, 2024
Build a real-time RAG chatbot using Google Drive and Sharepoint

newsMar 1, 2024
Pathway named as one of the French fastest-growing companies in 2023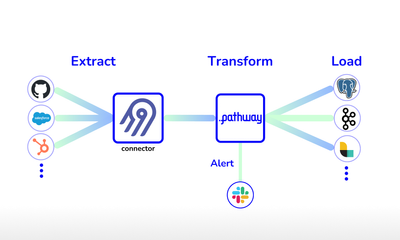

showcase · data-pipelineFeb 28, 2024
Streaming ETL pipelines in Python with Airbyte and Pathway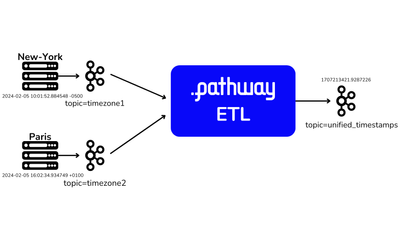
showcase · data-pipelineFeb 15, 2024
Kafka ETL: Processing event streams in Python

newsFeb 9, 2024
How Businesses Can Create Data Frameworks for Real-world AI

newsJan 21, 2024
Pathway positioned in the Unified Real-Time Platforms category
showcase · llmJan 12, 2024
Launching Pathway + LlamaIndex

blog · ragDec 29, 2023
Retrieval Augmented Generation: Beginner’s Guide to RAG Apps
newsDec 26, 2023
Gen AI Unleashed: Trends and Challenges for Enterprises in 2024, by Zuzanna Stamirowska, CEO of Pathway

podcastDec 25, 2023
Redefining AI’s Learning Curve: The Art of Unlearning

newsDec 22, 2023
Pathway highlighted in the TLDR newsletter in French


news · podcastDec 20, 2023
Pathway mentioned by 'Blef' in the DataGen Podcast around top data trends for 2024

newsDec 1, 2023
Client Testimonial: La Poste at Modern Data Stacktutorial · data-pipeline · showcaseNov 29, 2023
Working with live data streams in Jupyter
showcase · llmNov 28, 2023
Use LLMs to Ingest Raw Text into DB

newsNov 27, 2023
Pathway named as one of the best solutions in Data Orchestration in Supply chain

podcastNov 22, 2023
Guest speaker on the Digitalisation World podcast
showcase · llmNov 17, 2023
Use LLMs for notifications
tutorial · data-pipelineNov 16, 2023
Alerting on significant changes

blog · podcastNov 10, 2023
Guest speaker on The Futurists podcast
newsOct 23, 2023
Pathway is featured as a best-suited vendor candidate for Analytics and Decision Intelligence solutions for Supply Chain by Gartner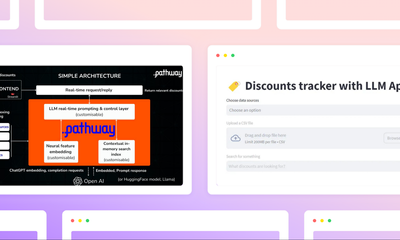

blogOct 19, 2023
How to build a real-time LLM app without vector databases
tutorial · Time SeriesOct 18, 2023
Real-time [Low-latency] Signal Processing in Streaming Mode: how to combine your Data Streams with upsampling.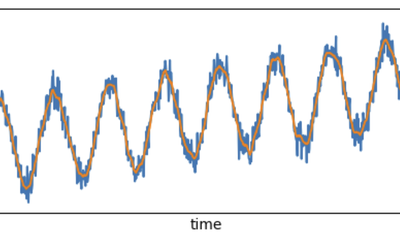
tutorial · Time SeriesOct 17, 2023
Real-time [Low-latency] Signal Processing in Streaming Mode: how to apply a Gaussian filter with irregular sampling in your Data Streams.
blogOct 16, 2023
Signal Processing in Real-time: Bridging the Gap Between Ideal Sampling and Real-World Data Streams
newsOct 16, 2023
Pathway named among the Top Startups Transforming the European business landscape
newsOct 11, 2023
A coffee with… Zuzanna Stamirowska
blogSep 29, 2023
Kafka vs RabbitMQ for Data Streaming
newsSep 25, 2023
Pathway appoints Head of Growth to drive US expansion and disrupt the AI data landscape
newsSep 24, 2023
Building Data Frameworks for Real-time AI Applications
newsAug 31, 2023
Enabling AI to unlearn and self-correct like a human
blog · tutorial · engineeringAug 28, 2023
How to use ChatGPT API in Python for your real-time data in French


newsAug 27, 2023
LLM and real-time learning article for 'La revue IA' in French

newsAug 25, 2023
Pathway quoted in Les Echos: Deeptech - the answer to tomorrow's challenges
blogAug 23, 2023
Building Enterprise Search APIs with LLMs for Production
newsAug 22, 2023
Pathway bring real-time value to logistics through machine unlearning
newsAug 21, 2023
How to Handle Out-of-Order Data in Your IoT Pipeline
newsAug 17, 2023
Pathway quoted in the FT: The skeptical case on generative AI
newsJul 26, 2023
Pathway named as a promising Generative AI leader (in French) in French
newsJul 26, 2023
French deep tech start-up announces the general launch of its data processing engine
newsJul 26, 2023
AI startup launches ‘fastest data processing engine’ on the market
blogJul 17, 2023
Pathway: Fastest Data Processing Engine - 2023 BenchmarksnewsJun 26, 2023
Pathway is a Representative Vendor in Gartner 2023 Market Guide for Analytics and Decision Intelligence Platforms in Supply Chain in French

newsJun 22, 2023
Pathway CEO featured in the ranking of the next generation of geniuses by the French national weekly Le PointblogJun 21, 2023
IoT Data Analytics: Processing Real-World Data in Real Time
blog · tutorialJun 16, 2023
Tutorial: Distributed computing with live streaming data
news · videoJun 16, 2023
Pathway awarded at VivaTech by the French Prime Minister Elisabeth Borne

tutorial · machine-learningMay 30, 2023
Tumbling Window group-by - detect suspicious user activity

blog · podcastMay 23, 2023
Guest Speaker on Intel Business Podcast with Darren Pulsipher, Chief Solutions Architect
newsMay 17, 2023
Founder profile: Zuzanna Stamirowska opening up to devmionewsMay 15, 2023
Pathway is Featured in Gartner’s Market Guide for Event Stream Processing in French
newsMay 15, 2023
Interview for Paris-Saclay
newsMay 11, 2023
Pathway Named as a Top Startup Disrupting Supply Chains
tutorial · engineeringMay 9, 2023
Unlocking data stream processing [Part 3] - data enrichment with fuzzy joinsTime SeriesApr 28, 2023
How to combine two time series
blog · podcastApr 26, 2023
Guest Speaker on Charbon Podcast (in French)
blog · podcastApr 11, 2023
Podcast speaker on SuperDataScience Podcast #669
blogApr 6, 2023
Improving asset utilization with Pathway: combining IoT data with real-time data processing
blog · tutorial · engineeringApr 5, 2023
What is Fuzzy Join and How Can it Help You Make Sense of Your Data? in French

newsApr 1, 2023
La Poste shared their IoT roadmap, and how Pathway helps them with their strategic objectives in French


newsMar 31, 2023
Interview for Emile Magazine, Sciences Po
blog · newsMar 9, 2023
Pathway featured in Sifted briefing on GenAI
tutorial · engineeringMar 9, 2023
Unlocking data stream processing [Part 2] - realtime server logs monitoring with a sliding window
tutorial · data-pipelineFeb 27, 2023
Realtime Server Log Monitoring
blog · podcastFeb 20, 2023
The value of real-time analytics - IoT for all podcast
tutorial · engineeringFeb 16, 2023
Unlocking data stream processing [Part 1] - real-time linear regression
blog · podcastFeb 11, 2023
Guest speakers on Female Foundry Podcast
blog · newsFeb 8, 2023
Guest speaker at Maddyness Keynote in French


newsJan 12, 2023
Zuzanna’s interview for Business Cool 
tutorial · data-pipelineJan 9, 2023
Mining hidden user pair activity with Fuzzy Join in French
.svg.png)
newsJan 9, 2023
Pathway in Les Echos - CEO Portraittutorial · data-pipelineDec 23, 2022
Linear regression on a Kafka stream
newsDec 6, 2022
Female-led deeptech startup Pathway announces its $4.5m pre-seed round
blog · open betaDec 5, 2022
Pathway is now in Open Beta
blog · video · podcastDec 2, 2022
Podcast speaker on Super Data Science PodcastblogDec 1, 2022
Pathway Premieres at PyData Global
tutorial · machine-learningNov 7, 2022
Computing PageRank
blog · newsNov 4, 2022
Pathway featured in Wavestone’s 2022 Data & AI radar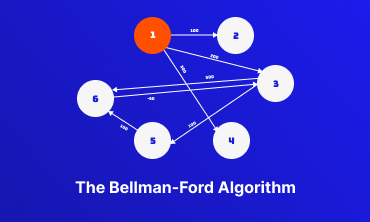
tutorial · machine-learningNov 3, 2022
Bellman-Ford Algorithm
tutorial · data-pipelineNov 1, 2022
Time between events in a multi-topic event stream
blog · cultureNov 1, 2022
Pathway at ODSC West
tutorial · machine-learning · showcaseOct 31, 2022
Realtime Twitter Analysis App
tutorial · machine-learningOct 31, 2022
Pathway Logistics Applicationtutorial · machine-learningOct 26, 2022
Realtime Classification with Nearest Neighbors (2/2)
tutorial · machine-learningOct 25, 2022
Realtime Classification with Nearest Neighbors (1/2)tutorial · data-pipelineOct 19, 2022
Part 2: Realtime Fuzzy-Jointutorial · data-pipelineOct 18, 2022
Part 1: Realtime Fuzzy-Join
blog · podcastOct 16, 2022
Discussing supply chain analytics on the Data Engineering Podcast
blog · video · podcastAug 1, 2022
Guest speaker on IoT For All Podcast
blogJun 1, 2022
Pathway graduated from CDL-Montreal!
blogJun 1, 2022
Pathway helps La Poste reduce IoT costs by 50%newsMay 30, 2022
Pathway on BFM Business - the French Business TV channel
blogMay 24, 2022
NavAlgo officially becomes Pathway!
blogMay 13, 2022
Pathway wins the #Spring50 Pitch Contest!
blogMar 1, 2022
Pathway is a WomenTech EU LaureateblogOct 19, 2021
Pathway is a Gartner Representative VendorblogOct 9, 2021
Pathway joins Agoranov, French Science and Tech incubator - in Paris, France
blogSep 27, 2021
Pathway has been selected by Hello Tomorrow as a Deep Tech Pioneer blogJul 9, 2021
Pathway named 2021 i-Lab Laureate