In the news
Read about Pathway’s latest media mentions, press releases and more!


news · podcastJan 6, 2026
This AI Grows a Brain During Training (Pathway's AI w/ Zuzanna Stamirowska)

newsDec 26, 2025
Tech That Will Change Your Life in 2026

newsDec 21, 2025
How 'Neolabs' Are Betting Against the OpenAI Model and What It Means for Founders

news · videoDec 4, 2025
AWS re:Invent 2025 -The new AI architecture that adapts and thinks just like humans
newsDec 1, 2025
Pathway Looks Toward the Post-Transformer Era

newsOct 10, 2025
100 Women in Tech

newsOct 8, 2025
Can AI Learn And Evolve Like A Brain? Pathway’s Bold Research Thinks So

news · podcastOct 7, 2025
Dragon Hatchling: The Missing Link Between Transformers and the Brain, with Adrian Kosowski (SDS 929)

tutorial · engineeringAug 22, 2025
Pathway MCP Server: Live Indexing & Analytics for your Agents

blog · engineeringJul 17, 2025
50× Faster Local Embeddings with Batch UDFs

news · podcastJul 9, 2025
New podcast: Europe’s AI opportunity

newsJun 22, 2025
La Poste partners with Pathway to create digital twin of fleet
tutorial · engineeringMay 30, 2025
Real-Time Multimodal Data Processing with Pathway and Docling

newsMay 16, 2025
Opinion: EU could be epicenter of AI academia as US cuts funding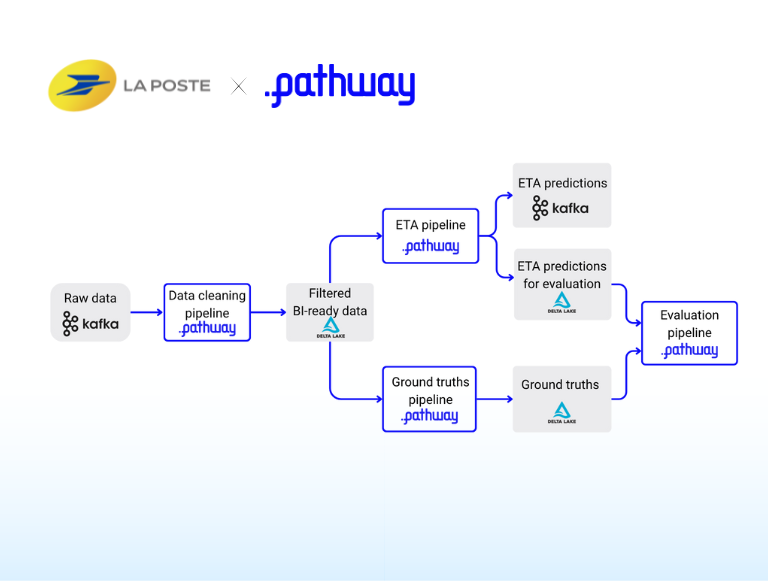

showcase · data-pipelineMay 15, 2025
How La Poste uses Pathway microservices to deliver high-quality ETAs

news · case-studyApr 23, 2025
Transdev and Pathway partner to improve mobility and public transport performance through LiveAI™
newsApr 17, 2025
Transdev and Pathway partner to improve mobility and public transport performance through LiveAI™

newsApr 17, 2025
From Data-sure To AI-savvy: Unlocking The Next Stage Of Business Transformation

newsApr 1, 2025
Victor Szczerba assumes CCO role at Pathway post funding in Polish
newsMar 20, 2025
Forbes Poland: CEO profile (in Polish)

newsMar 19, 2025
Embracing Modern Live Data Pipelines is Key to Scaling Enterprise AI
news · podcastMar 13, 2025
Data Sommelier Podcast Episode 1 Season 2
video · tutorial · engineeringMar 13, 2025
Build RAG Apps in YAML - Recording from the Intel AI DevSummit
showcase · llm · engineeringMar 13, 2025
Evaluating RAG applications with RAGAS
news · videoMar 4, 2025
La Poste Optimizes Colissimo Flows in Real Time - Modern Data Stack Recording available
newsFeb 27, 2025
Becoming AI-savvy: going beyond data smarts for business transformation
newsletterFeb 25, 2025
Pathway to the Silicon Valley
blog · engineeringFeb 20, 2025
Gemini 2.0 for Document Ingestion and Analytics with Pathway
newsFeb 13, 2025
Forbes: Pathway Navigates Next Road For AI Foundational Models
newsFeb 12, 2025
Pathway at the AI Action Summit! 

blog · tutorialFeb 11, 2025
Pathway’s Apache Iceberg Connectors for Real-Time Data Pipelines
blog · tutorial · engineeringFeb 5, 2025
Real-Time AI Pipeline with DeepSeek, Ollama and Pathway
blog · engineeringJan 16, 2025
Power and Deploy RAG Agent Tools with Pathway

newsDec 20, 2024
Pathway featured in Maddyness 2025 Insights and Predictions

blogDec 20, 2024
2025 PATHWAY CEO PREDICTIONS
newsDec 19, 2024
Pathway CEO and co-founder predicts 2025 AI trends: Will your startup survive the shift?

tutorialDec 11, 2024
Scalable Alternative to Apache Kafka and Flink for Advanced Streaming: Build Real-Time Systems with NATS and Pathway

newsDec 6, 2024
CNBC India spotlighting Pathway

newsDec 4, 2024
ETCIO Southeast Asia covers Pathway Seed Round
newsDec 2, 2024
Parisian AI startup Pathway on moving to the US: 'We need to be in the room where it happens, and it happens in the Bay Area
newsDec 2, 2024
Pathway raises $10 million in seed funding round

newsNov 29, 2024
As Cohere and Writer mine the ‘LiveAI™’ arena, Pathway joins the pack with a $10M round

newsNov 29, 2024
Industry Leaders Comment On Biggest Lessons From ChatGPT’s Journey So Far
newsNov 27, 2024
Pathway is Now Available on Microsoft Azure!

newsNov 14, 2024
Gartner® recognizes Pathway as an Emerging Visionary in GenAI Engineering
news · case-studyNov 13, 2024
Joint Support and Enabling Command collaborates with AI company Pathway to combine industry and military expertise

video · podcastNov 13, 2024
Harnessing the Power of Now With Real-Time Analytics with Zuzanna Stamirowska & Hélène Stanway
news · engineeringOct 29, 2024
Build LLM/RAG pipelines with YAML templates by Pathway

news · case-studySep 23, 2024
Pathway Slide Search is now available on Intel Tiber Cloud
newsSep 2, 2024
Pathway showcased during Intel AI Summit
newsAug 29, 2024
Pathway Joins Linux Foundation’s OPEA alongside Intel and HuggingFace
tutorial · engineering · case-studyAug 27, 2024
Achieve Sub-Second Latency with your S3 Storage without Kafka
newsAug 16, 2024
Pathway is available on AWS Cloud!

tutorial · engineeringAug 6, 2024
Computing the Option Greeks using Pathway and Databento
showcase · llmAug 6, 2024
Multimodal RAG with Gemini
showcase · llm · case-study · engineeringJul 15, 2024
Real-time Enterprise RAG with SharePointnewsJun 1, 2024
Pathway has been selected for Intel Liftoff

video · podcastMay 22, 2024
BNP Paribas Talk: AI and Real-time data processing in the banking industry, Vivatech 2024
showcase · llm · engineeringMay 18, 2024
Langchain and Pathway: RAG Apps with always-up-to-date knowledge
newsApr 30, 2024
The Future of Large Language Models by Lukasz Kaiser and Jan Chorowski
blog · case-studyApr 29, 2024
Building End-to-End RAG with NPCI’s AI Leader

blogApr 19, 2024
Machine Unlearning for LLMs: Build Apps that Self-Correct in Real-Time 
blogApr 18, 2024
Batch processing vs stream processingnewsApr 17, 2024
Pathway has been selected for the Intel’s accelerator program for deep tech startups
case-studyApr 16, 2024
The Power of Real-Time Visualization for Logistics IoTnewsletterApr 12, 2024
4x LLM token cost reduction, Secure local RAG applications, and Bay Area Meetup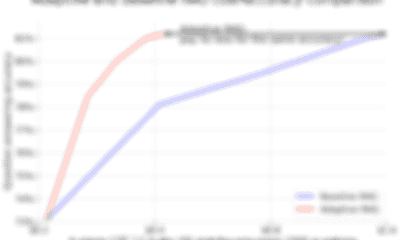

blog · feature · engineering · tutorial · case-studyMar 28, 2024
Adaptive RAG: cut your LLM costs without sacrificing accuracy
blogMar 21, 2024
Supply Chain Optimization with Integrated IoT Data
blog · case-studyMar 7, 2024
Build a real-time RAG chatbot using Google Drive and Sharepoint

newsMar 1, 2024
Pathway named as one of the French fastest-growing companies in 2023newsletterFeb 15, 2024
Preparing for 2024 Olympics | Real-time RAG: A Spreadsheet is All You Need | ETL in Kafka
newsFeb 9, 2024
How Businesses Can Create Data Frameworks for Real-world AI
news · case-studyJan 31, 2024
Pathway at Modern Data Stack Meetup: Enabling Real-Time Operational Analytics for La Poste Groupe
news · case-studyJan 26, 2024
Transdev Project kickoff in Dunkirk, France
newsJan 21, 2024
Pathway positioned in the Unified Real-Time Platforms category
showcase · llm · case-study · engineeringJan 12, 2024
LlamaIndex and Pathway: RAG Apps with always-up-to-date knowledge

newsJan 8, 2024
LLM series - Pathway: Taking LLMs out of pilot into production
blog · ragDec 29, 2023
Retrieval Augmented Generation: Beginner’s Guide to RAG AppspathwayDec 29, 2023
RAG - Streaming Application Pathway Legal Assistant
newsDec 26, 2023
Gen AI Unleashed: Trends and Challenges for Enterprises in 2024, by Zuzanna Stamirowska, CEO of Pathway

podcastDec 25, 2023
Redefining AI’s Learning Curve: The Art of Unlearning

newsDec 22, 2023
Pathway highlighted in the TLDR newsletter in French


news · podcastDec 20, 2023
Pathway mentioned by 'Blef' in the DataGen Podcast around top data trends for 2024

newsDec 1, 2023
Client Testimonial: La Poste at Modern Data StacknewsletterNov 30, 2023
Streaming meets AI: Live Jupyter dashboards, LLM alerts, and more

newsNov 27, 2023
Pathway named as one of the best solutions in Data Orchestration in Supply chain

podcastNov 22, 2023
Guest speaker on the Digitalisation World podcast
newsNov 14, 2023
Finalist of the NATO Innovation Challenge!

blog · podcastNov 10, 2023
Guest speaker on The Futurists podcast
newsOct 23, 2023
Pathway is featured as a best-suited vendor candidate for Analytics and Decision Intelligence solutions for Supply Chain by Gartner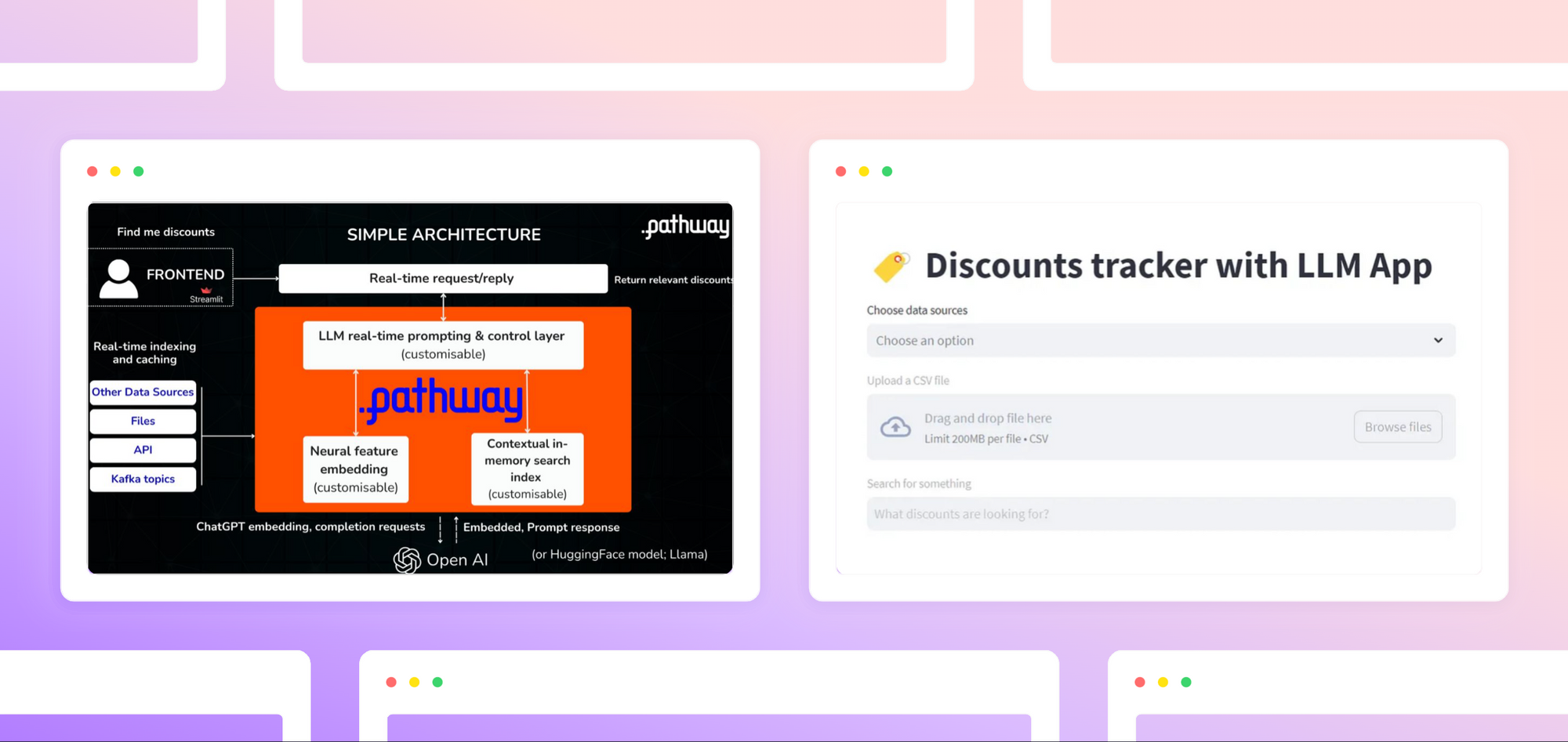

blogOct 19, 2023
How to build a real-time LLM app without vector databases

newsOct 16, 2023
Pathway named among the Top Startups Transforming the European business landscape
blogOct 16, 2023
Signal Processing in Real-time: Bridging the Gap Between Ideal Sampling and Real-World Data Streams

newsOct 11, 2023
A coffee with… Zuzanna Stamirowska
blogSep 29, 2023
Kafka vs RabbitMQ for Data Streaming
newsSep 24, 2023
Building Data Frameworks for Real-time AI Applications
newsAug 31, 2023
Enabling AI to unlearn and self-correct like a human
blog · tutorial · engineeringAug 28, 2023
How to use ChatGPT API in Python for your real-time data in French

newsAug 27, 2023
LLM and real-time learning article for 'La revue IA' in French

newsAug 25, 2023
Pathway quoted in Les Echos: Deeptech - the answer to tomorrow's challenges
blogAug 23, 2023
Building LLM enterprise search APIs
newsAug 22, 2023
Pathway bring real-time value to logistics through machine unlearning
newsAug 21, 2023
How to Handle Out-of-Order Data in Your IoT Pipeline
newsAug 17, 2023
Pathway quoted in the FT: The skeptical case on generative AInewsletterJul 26, 2023
Pathway: Gartner, Redpanda, Intel and more
newsJul 26, 2023
AI startup launches ‘fastest data processing engine’ on the market in French
newsJul 26, 2023
French deep tech start-up announces the general launch of its data processing engine
newsJul 26, 2023
Pathway named as a promising Generative AI leader (in French)
blogJul 17, 2023
Pathway: Fastest Data Processing Engine - 2023 BenchmarksnewsJun 26, 2023
Pathway is a Representative Vendor in Gartner 2023 Market Guide for Analytics and Decision Intelligence Platforms in Supply Chain in French

newsJun 22, 2023
Pathway CEO featured in the ranking of the next generation of geniuses by the French national weekly Le PointblogJun 21, 2023
IoT Data Analytics: Processing Real-World Data in Real Time
news · videoJun 16, 2023
Pathway awarded at VivaTech by the French Prime Minister Elisabeth Borne
blog · tutorialJun 16, 2023
Tutorial: Distributed computing with live streaming datanewsletterMay 26, 2023
Pathway is the most powerful: benchmarks & real-time LLMs

blog · podcastMay 23, 2023
Guest Speaker on Intel Business Podcast with Darren Pulsipher, Chief Solutions Architect
newsMay 17, 2023
Founder profile: Zuzanna Stamirowska opening up to devmio in French
newsMay 15, 2023
Interview for Paris-Saclay
newsMay 15, 2023
Pathway is Featured in Gartner’s Market Guide for Event Stream Processing
newsMay 11, 2023
Pathway Named as a Top Startup Disrupting Supply Chains
tutorial · engineeringMay 9, 2023
Unlocking data stream processing [Part 3] - data enrichment with fuzzy joins in French

blog · podcastApr 26, 2023
Guest Speaker on Charbon Podcast (in French)
blog · podcastApr 11, 2023
Podcast speaker on SuperDataScience Podcast #669
blogApr 6, 2023
Improving asset utilization with Pathway: combining IoT data with real-time data processing
blog · tutorial · engineeringApr 5, 2023
What is Fuzzy Join and How Can it Help You Make Sense of Your Data? in French

newsApr 1, 2023
La Poste shared their IoT roadmap, and how Pathway helps them with their strategic objectives in French


newsMar 31, 2023
Interview for Emile Magazine, Sciences Po
tutorial · engineeringMar 9, 2023
Unlocking data stream processing [Part 2] - realtime server logs monitoring with a sliding window
blog · newsMar 9, 2023
Pathway featured in Sifted briefing on GenAI
blog · podcastFeb 20, 2023
The value of real-time analytics - IoT for all podcast
tutorial · engineeringFeb 16, 2023
Unlocking data stream processing [Part 1] - real-time linear regression
blog · podcastFeb 11, 2023
Guest speakers on Female Foundry Podcast
blog · newsFeb 8, 2023
Guest speaker at Maddyness KeynotenewsletterJan 24, 2023
Pathway - a message from the CEO in French


newsJan 12, 2023
Zuzanna’s interview for Business Cool in French
.svg.png)
newsJan 9, 2023
Pathway in Les Echos - CEO Portrait
newsDec 6, 2022
Female-led deeptech startup Pathway announces its $4.5m pre-seed round
blog · open betaDec 5, 2022
Pathway is now in Open Beta
blog · video · podcastDec 2, 2022
Podcast speaker on Super Data Science PodcastblogDec 1, 2022
Pathway Premieres at PyData Global
blog · newsNov 4, 2022
Pathway featured in Wavestone’s 2022 Data & AI radar
blog · cultureNov 1, 2022
Pathway at ODSC Westtutorial · machine-learningOct 26, 2022
Realtime Classification with Nearest Neighbors
blog · podcastOct 16, 2022
Discussing supply chain analytics on the Data Engineering Podcast
blog · video · podcastAug 1, 2022
Guest speaker on IoT For All Podcast
blogJun 1, 2022
Pathway helps La Poste reduce IoT costs by 50%
blogJun 1, 2022
Pathway graduated from CDL-Montreal!newsMay 30, 2022
Pathway on BFM Business - the French Business TV channel
blogMay 24, 2022
Why Pathway
blogMay 13, 2022
Pathway wins the #Spring50 Pitch Contest!
blogMar 1, 2022
Pathway is a WomenTech EU LaureateblogOct 19, 2021
Pathway is a Gartner Representative VendorblogOct 9, 2021
Pathway joins Agoranov, French Science and Tech incubator - in Paris, France
blogSep 27, 2021
Pathway has been selected by Hello Tomorrow as a Deep Tech Pioneer blogJul 9, 2021
Pathway named 2021 i-Lab LaureateShowing 155 of 170 results